




苹果研究人员合著的一项新研究表明,在要求开源大语言模型(LLM)使用一项简单的生产力技巧检查自身工作后,其性能获得了显著提升。详情如下。
背景信息
大语言模型完成训练后,通常需要通过人类反馈强化学习(RLHF)这一训练后步骤来进一步提升质量。
通过RLHF,每当模型给出答案时,人类标注员可以给予点赞(奖励)或点踩(惩罚)。随着时间的推移,模型逐渐学会哪些答案更容易获得点赞,从而整体实用性得到提升。
这种训练后阶段部分属于更广泛的“对齐”领域,该领域探索使大语言模型行为既有用又安全的方法。
未对齐的模型可能会学会欺骗人类获取点赞——生成表面正确但并未真正解决问题的输出结果。
当然,在预训练、训练和训练后阶段存在多种提高模型可靠性和对齐度的方法。但本研究主要聚焦RLHF。
苹果研究
在这项名为《清单优于奖励模型:大语言模型对齐新方案》的研究中,苹果提出了一种基于清单的强化学习方案——清单反馈强化学习(RLCF)。
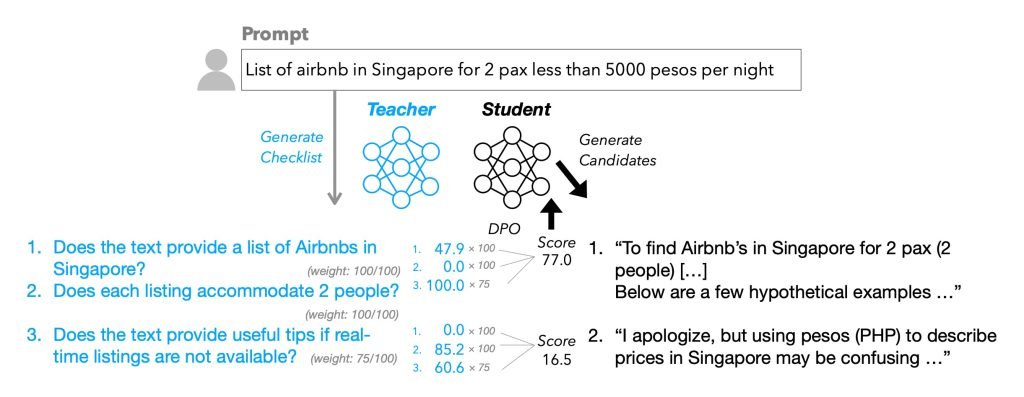
RLCF按照0-100分制评估响应满足清单各项要求的程度,初步结果令人鼓舞。研究人员解释道:
“我们在五个广泛研究的基准测试中,将RLCF与其他对齐方法应用于强指令跟随模型(Qwen2.5-7B-Instruct)进行对比——RLCF是唯一在所有基准测试中均提升性能的方法,包括在FollowBench上硬满意度提升4个百分点,InFoBench提高6个百分点,Arena-Hard获胜率上升3个百分点。这些结果表明清单反馈是提升语言模型对多需求查询支持能力的关键工具。”
最后一点对AI助手尤为重要,这将成为未来数百万用户与设备交互的标准底层接口。
研究人员进一步强调:
语言模型必须遵循用户指令才能体现价值。随着公众将基于语言模型的助手融入日常任务处理,用户期望模型能忠实执行请求。当用户对模型处理复杂请求的能力越有信心,就越会赋予需要谨慎关注细节的丰富多步指令。
生成正确清单
该研究另一个亮点在于清单的生成方式及各条目权重分配机制。
这当然需要借助大语言模型实现。基于前人研究,苹果研究人员为13万条指令生成清单(…)创建了新数据集WildChecklists。使用Qwen2.5-0.5B至7B等模型生成候选响应,并以Qwen2.5-72B-Instruct作为清单生成模型(…)。
简而言之,研究人员自动为每条用户指令附加包含具体是/否要求的微型清单(例如:“是否翻译为西班牙语?”)。随后,更大的教师模型根据清单条目对候选响应评分,这些加权分数成为微调学生模型的奖励信号。
成果与局限
通过建立最佳清单生成系统,研究人员在某个基准测试中实现了8.2%的性能提升。不仅如此,与其他方法相比,该方案在多个基准测试中均领先。
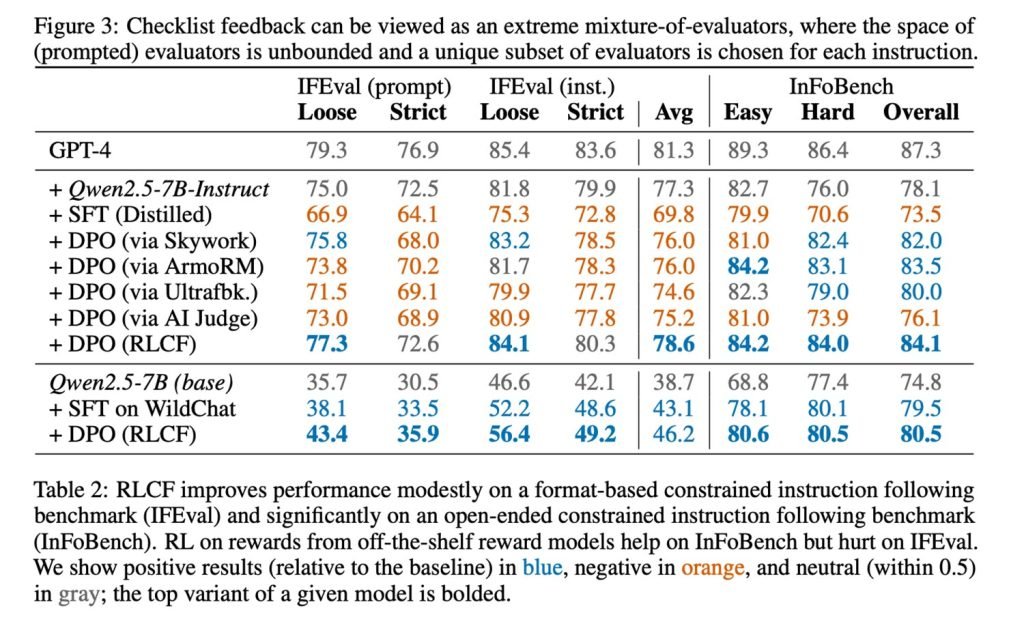
研究人员指出,本研究专注于“复杂指令跟随”,RLCF可能不适用于其他场景的强化学习技术。他们还提到该方法需使用更强大的模型作为评判者来调优小模型,这也是显著局限。最重要的是,他们明确表示“RLCF旨在提升复杂指令跟随能力,而非安全对齐”。
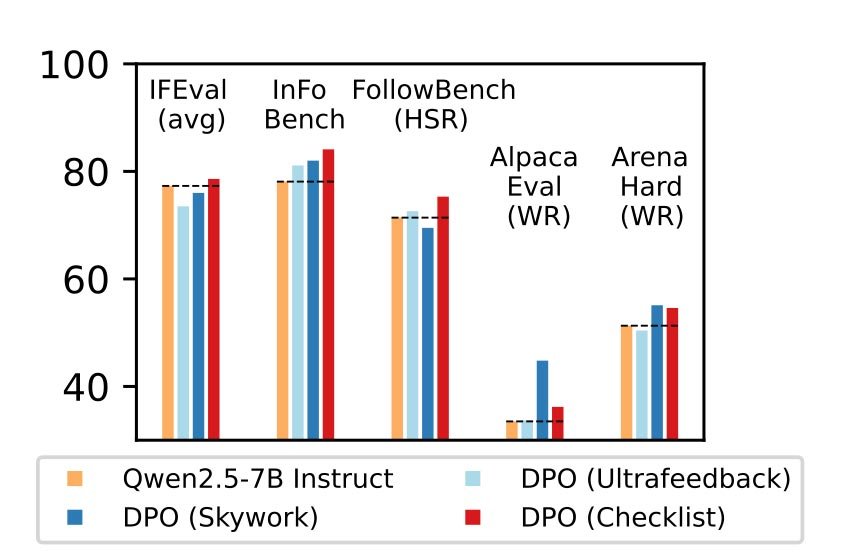
尽管如此,这项研究为提升人机交互可靠性提供了一种新颖(却简单)的方法,这将是人类与基于LLM的助手互动中最关键的环节。
随着这些助手逐渐获得代理能力,指令跟随(与对齐)将愈发重要,这使得该研究更具现实意义。