





苹果研究人员开发了SlowFast-LLaVA模型的改进版本,在长视频分析与理解任务上超越更大规模模型。以下是具体解读。
技术原理
当大型语言模型被训练理解视频时,其基本流程包括:将视频分割为帧序列,运用计算机视觉提取视觉特征,分析这些特征的时序变化,并将所有信息与语言对齐,从而以文本形式描述或推理视频内容。
低效的处理方式是对每帧画面进行分析,这会产生海量冗余信息——因为相邻帧之间往往只有微小变化。当信息量超过模型的上下文窗口(即单次处理信息的极限容量)时,模型会逐步丢弃早期信息以容纳新内容。
当然存在更高效的视频语言模型训练方案(英伟达近期就相关主题发表了论文),但上述基础原理有助于理解苹果的研究。
苹果的研究突破
正如研究人员在论文《SlowFast-LLaVA-1.5:面向长视频理解的高效令牌视频大语言模型家族》中所述:
“视频大语言模型(Video LLMs)将视频感知能力整合至预训练LLM中,用以处理视频并响应指令。尽管取得显著进展,现有视频LLM仍存在明显局限性。”
主要局限体现在三方面:
- 现有模型过度依赖长上下文窗口与大量帧采样,效率低下且难以迁移至小模型;
- 多数方案需复杂多阶段训练流程(常使用私有数据集),难以复现;
- 许多模型仅针对视频任务优化,限制了其作为通用多模态模型的图像理解能力。
为解决这些问题,苹果基于开源模型SlowFast-LLaVA进行改进。该模型通过双流架构结合时空信息:慢流通道以高细节解析关键帧捕捉场景内容,快流通道以低细节采样更多帧追踪运动变化。
研究团队首先对模型进行图像微调以构建通用视觉推理能力,随后使用公开数据集联合训练图像与视频任务,使其在掌握时序结构的同时保持图像理解能力。
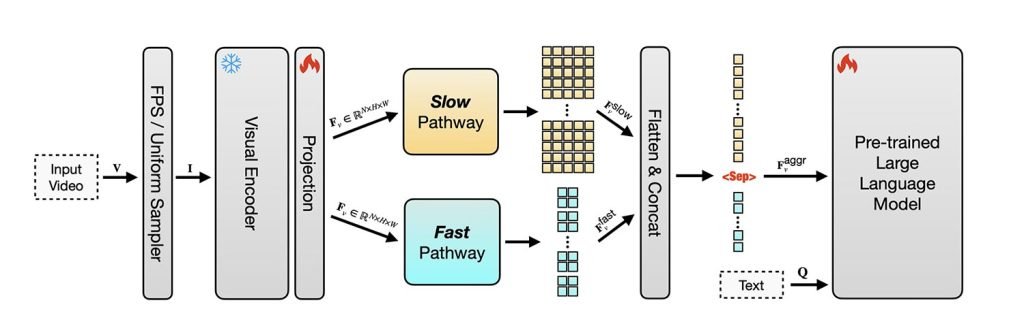
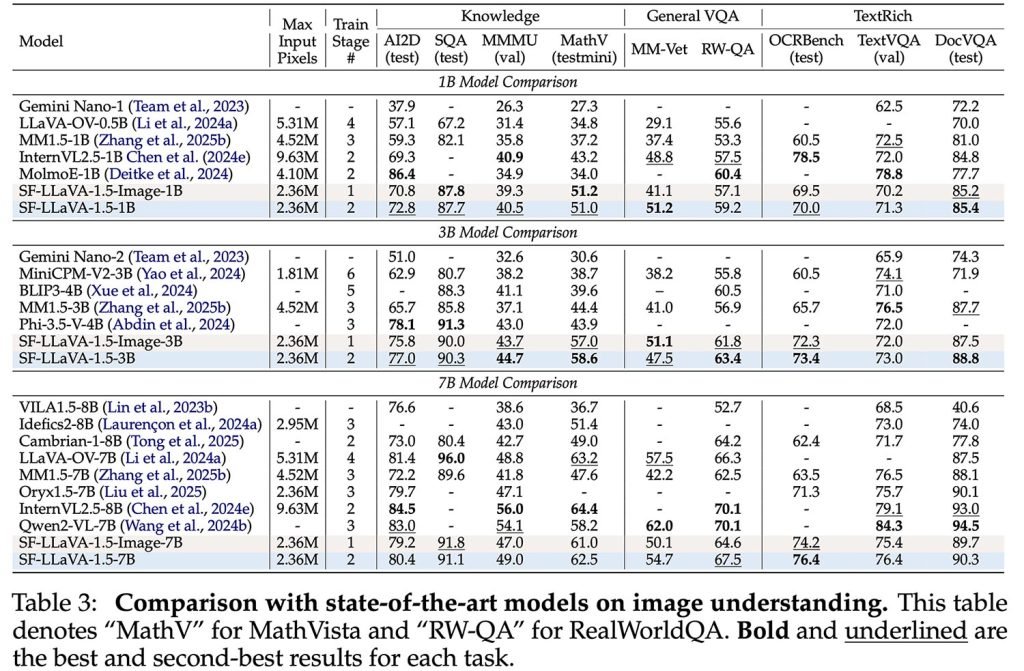
最终成果SlowFast-LLaVA-1.5(SF-LLaVA-1.5)包含10亿、30亿和70亿参数版本,在多项视频任务中超越更大规模模型,研究人员称其优势有时“非常显著”。
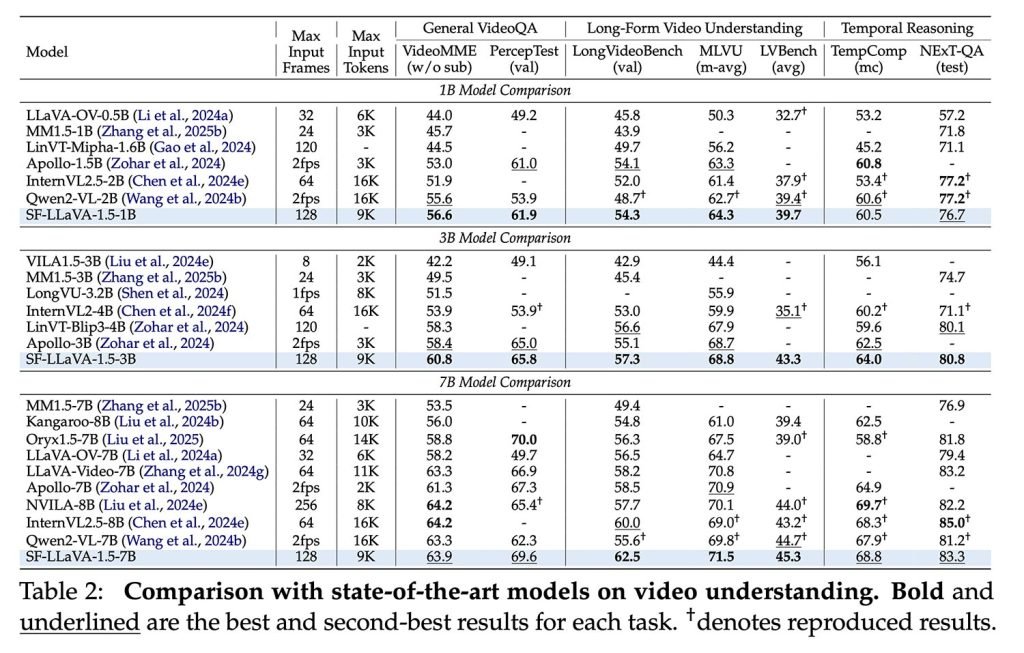
在LongVideoBench和MLVU等长视频基准测试中,该模型所有尺寸版本均刷新最高纪录,包括最小的10亿参数模型。
更重要的是,该模型同时克服了前述三大局限之一,在图像任务(包括知识问答、数学推理、OCR和文本密集场景)中同样表现优异。
研究团队测试了多种视频压缩策略,最终方案在速度、精度与令牌数量间实现了最佳平衡。
现存局限性
SF-LLaVA-1.5设定了128帧的最大输入长度——无论处理几分钟还是几小时视频,始终从快流通道选取96帧均匀采样,慢流通道选取32帧均匀采样。
研究人员指出:
“这种方式可能遗漏长视频中的关键帧,并对视频播放速度产生误判。(…) 通过调优视觉编码器等全部参数可进一步提升性能,但长视频LLM的GPU内存消耗使得全参数调优极具挑战。未来研究可探索随机反向传播等内存优化技术。”
尽管存在局限,该模型仍凭借完全基于公开数据集训练的优势成为当前最优方案。SF-LLaVA-1.5已开源发布于GitHub和Hugging Face平台,完整论文可查阅arXiv。
以下为模型实际应用示例: