





一项新研究显示,苹果研究团队采用了一种非常有趣的方法:让开源模型自主学习如何使用SwiftUI构建优质界面。以下是他们的实现路径
在论文《UICoder:通过自动化反馈微调大语言模型生成用户界面代码》中,研究人员指出,虽然大语言模型在创意写作和编程等多项写作任务上表现更佳,但仍难以”可靠生成语法正确、设计优良的UI代码”。他们也找到了症结所在:
即使在精选或人工编写的微调数据集中,UI代码样本也极其稀少,在某些代码数据集中占比不足1%。
为此,他们以专攻编程的开源模型StarChat-Beta为基础,提供UI描述列表,指导其根据描述生成大量SwiftUI程序合成数据集。
随后,他们通过Swift编译器验证每段代码的可执行性,再由视觉语言模型GPT-4V将编译界面与原始描述进行比对分析。
无法编译、无关或重复的输出均被剔除,剩余输出构成高质量训练集用于模型微调。
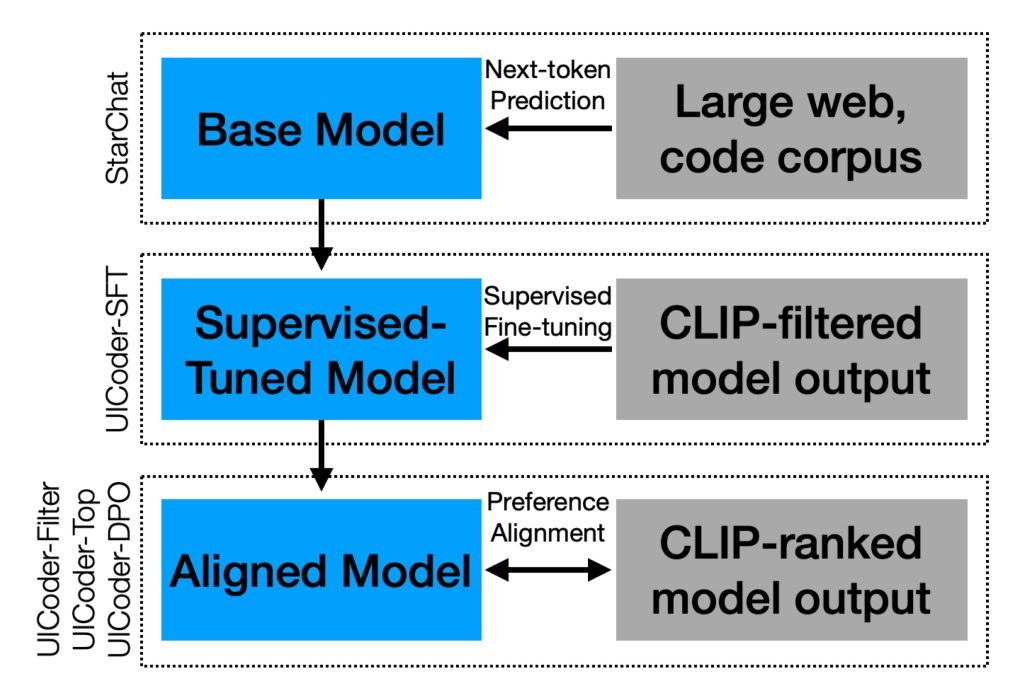
经过多次迭代发现,改进后的模型生成的SwiftUI代码质量持续提升,进而形成更纯净的数据集。
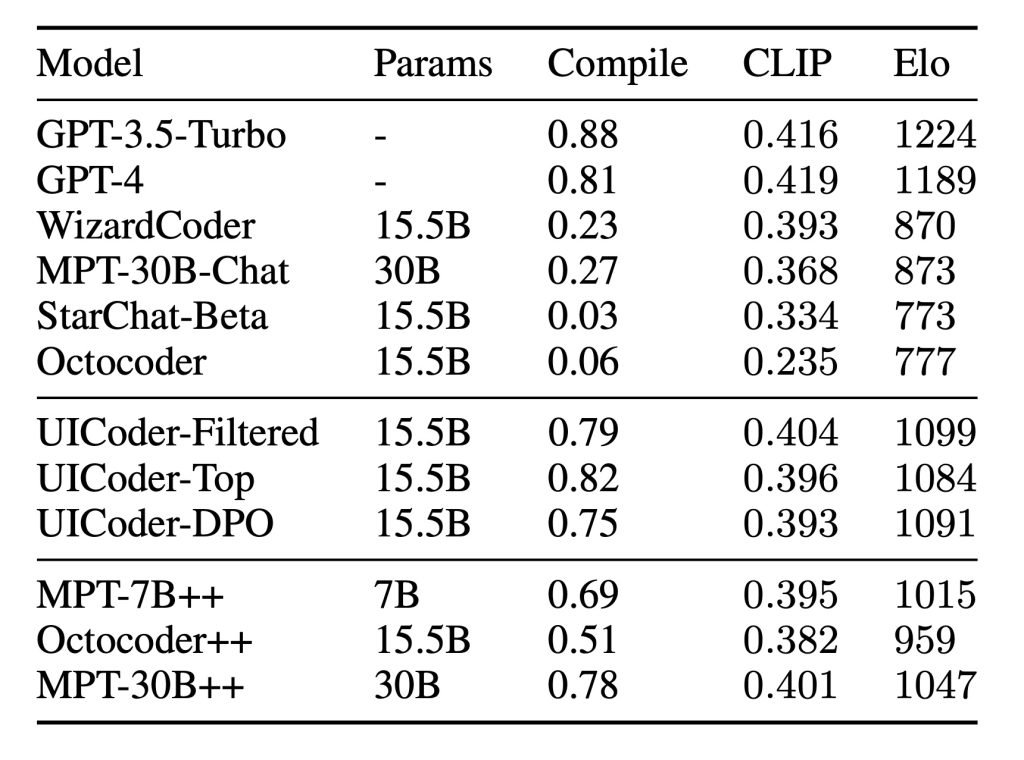
五轮训练后,他们获得了近百万个SwiftUI程序(精确数字为996,000个)和名为UICoder的模型。相比初始模型,UICoder能稳定编译并生成更贴近提示词的界面。
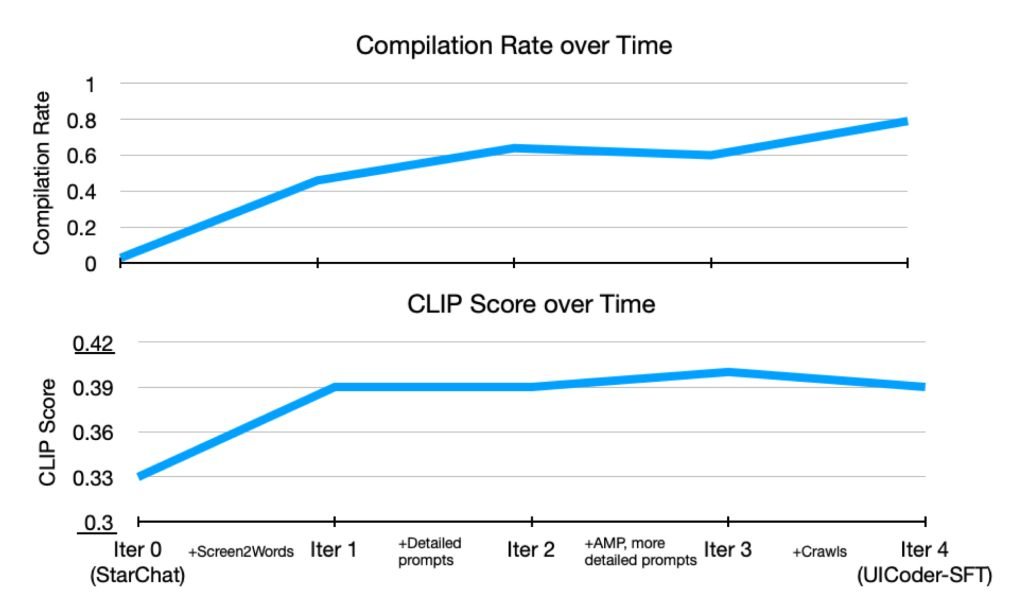
测试表明,UICoder在自动化指标和人工评估中均显著优于基础模型StarChat-Beta。
UICoder整体质量接近GPT-4,编译成功率甚至实现反超。
关键发现:原始数据集意外遗漏SwiftUI代码
研究中有个意外插曲:StarChat-Beta基础模型主要基于三个数据源训练:
- 许可代码仓库大型数据集TheStack(2500亿标记);
- 网络爬取页面;
- 小型指令调优数据集OpenAssistant-Guanaco。
但苹果团队发现:
StarChat-Beta训练数据几乎不含SwiftUI内容。构建TheStack数据集时意外排除了Swift代码仓库,而OpenAssistant-Guanaco数据集中仅万分之一的响应样本包含Swift代码。我们推测模型训练中接触的Swift样本主要来自网络爬取,其质量与结构化程度可能低于仓库代码。
这意味着UICoder的进步并非基于既有SwiftUI样本(原始训练数据中几乎没有),而是源自苹果通过自动化反馈循环构建的自生成精选数据集。
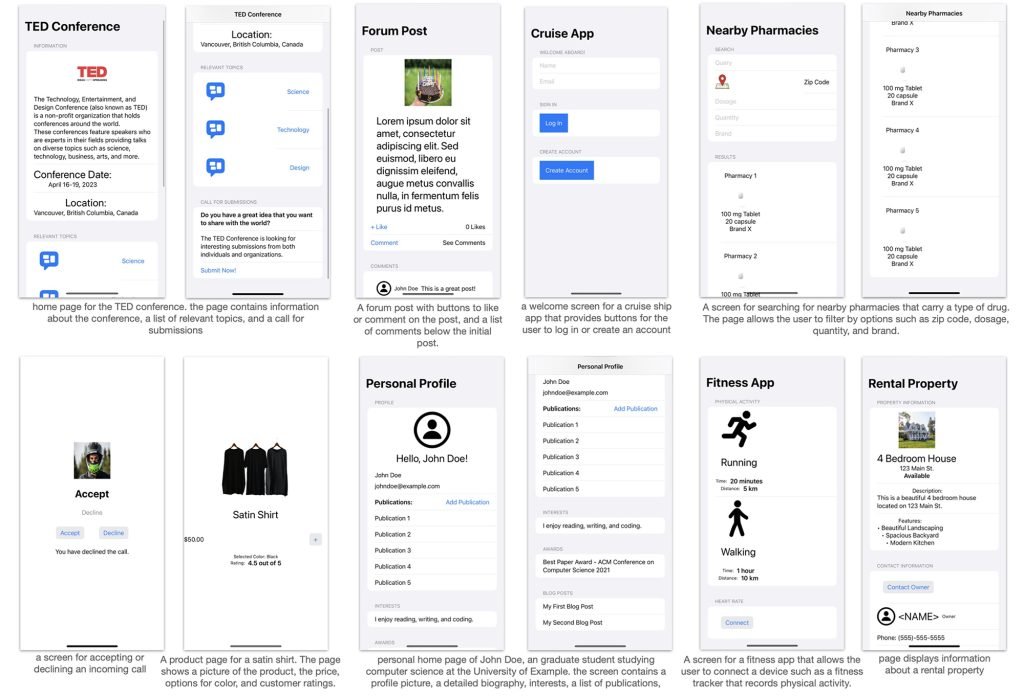
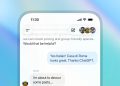
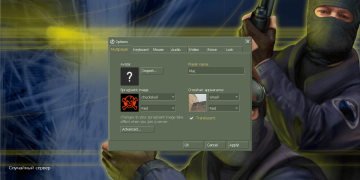
研究说明:”模型生成的SwiftUI代码渲染效果截图。为展示效果我们手动添加了素材图片和图标,除更新图像资源名称外未对代码做任何修改。”
研究人员由此推测,该方法虽针对SwiftUI实现,但”很可能适用于其他语言和UI工具包”。
论文《UICoder:通过自动化反馈微调大语言模型生成用户界面代码》已发布于arXiv平台。