





苹果在Hugging Face平台低调发布了一款具有突破性的AI模型。与传统大语言模型按顺序生成代码(从左到右,自上而下)不同,该模型能够非顺序编写代码,并同时优化多个代码块。
这使得代码生成速度显著提升,性能足以匹敌顶尖开源编程模型。以下是其工作原理。
技术核心
在深入探讨前,我们需要理解几个关键概念(为便于理解已做简化处理)。
自回归模型
传统大语言模型多采用自回归方式。当接收到问题时,模型会先处理整个问题,预测答案的第一个标记,然后结合首个标记重新处理问题,再预测第二个标记,以此类推。这种机制使其像人类阅读般生成文本:从左到右,自上而下。
温度参数
大语言模型设有温度参数控制输出随机性。在预测下一个标记时,模型会为所有可能选项分配概率值。较低温度倾向于选择最高概率的标记,较高温度则允许选择低概率选项。
扩散模型
与自回归模型相对的扩散模型,更常见于Stable Diffusion等图像模型。简言之,模型从模糊噪点图像出发,在迭代过程中根据用户需求逐步降噪,最终生成符合要求的清晰图像。

扩散模型在数据与噪点间的转换过程。图片来源:NVIDIA
理解了吗?精彩继续!
近期,部分大语言模型开始尝试扩散架构生成文本,成效显著。如需深入了解其原理,这里有个绝佳解析:
为何强调这些?因为基于扩散的文本模型能并行优化整个文本,理论上比自回归模型更高效。
这种特性尤其适合编程场景,全局结构优化比线性标记预测更为重要。
重点来了:苹果发布了什么模型?
苹果开源了名为DiffuCode-7B-cpGRPO的模型,其理论基础来自上月发表的论文《DiffuCoder:面向代码生成的掩码扩散模型优化研究》。
该论文描述了一种采用扩散优先策略的代码生成模型,但存在关键创新:
“当采样温度从默认值0.2提升至1.2时,DiffuCoder能够突破严格从左到右的限制,实现更灵活的标记生成顺序”
这意味着通过调节温度参数,该模型可在自回归与非顺序生成模式间自由切换。高温赋予其乱序生成能力,低温则保持传统解码方式。
配合耦合-GRPO训练技术,模型能以更少迭代生成更优质代码。最终成果?快速生成、全局连贯、且足以媲美顶尖开源编程模型的代码能力。
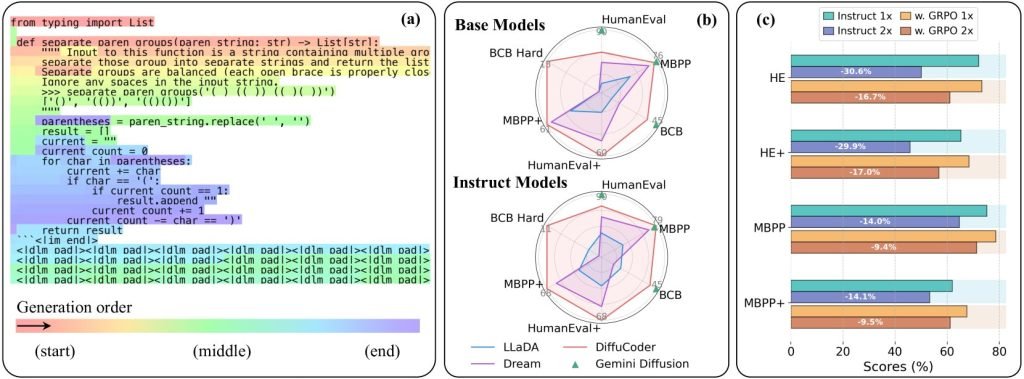
研究数据显示:”(a)温度1.2时DiffuCoder-Instruct的解码过程实例 (b)代码基准测试结果 (c)解码步骤减半时,采用耦合-GRPO训练的DiffuCoder-Instruct性能衰减更小”
基于阿里巴巴开源模型构建
更值得注意的是,苹果模型基于阿里巴巴开源基础模型Qwen2.5‑7B开发。阿里首先将其微调为Qwen2.5‑Coder‑7B提升代码能力,苹果在此基础上进行二次改造。
苹果先将其改造成扩散式解码器架构(如DiffuCoder论文所述),再针对指令跟随进行优化,最后使用2万多个精选编程案例进行专项训练。

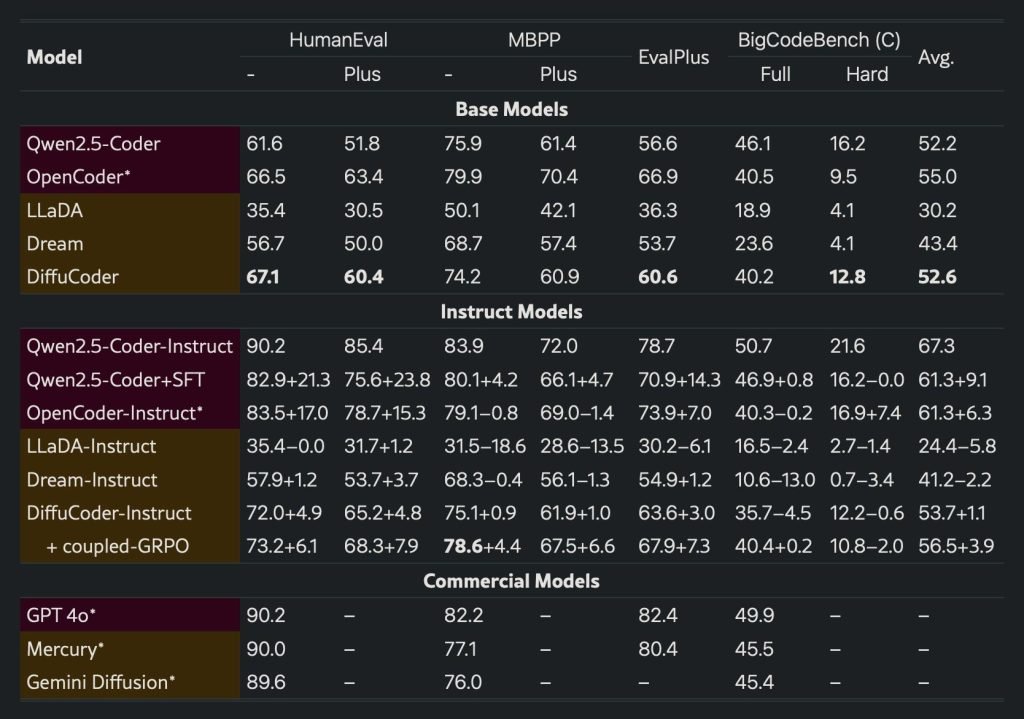
这些努力成效显著。DiffuCoder-7B-cpGRPO在主流编程基准测试中提升4.4%,同时保持对严格顺序生成的低依赖性。
当然仍有提升空间。尽管DiffuCoder优于多数扩散式编程模型(这还是在4.4%提升前),但仍未达到GPT-4或Gemini Diffusion的水平。
虽然有人指出70亿参数可能受限,或其扩散生成仍类似序列过程,但更重要在于:苹果正通过一系列创新理念,逐步夯实其生成式AI的技术基础。
至于这些技术何时(或是否)能转化为面向用户和开发者的实际功能与产品,则是另一个话题了。