





这苹果研究院团队发布了一个非常有趣的研究该研究调查了 AI 模型是否可以从听诊器记录中估计心率,即使它们没有经过专门训练以考虑此目的。简短的回答是:是的。这就是伟大新闻。原因如下。
简而言之,该团队采用了六个流行的音频或语音训练基础模型,并测试了它们的内部音频表示在多大程度上可用于从心音记录或心音图中估计心率。
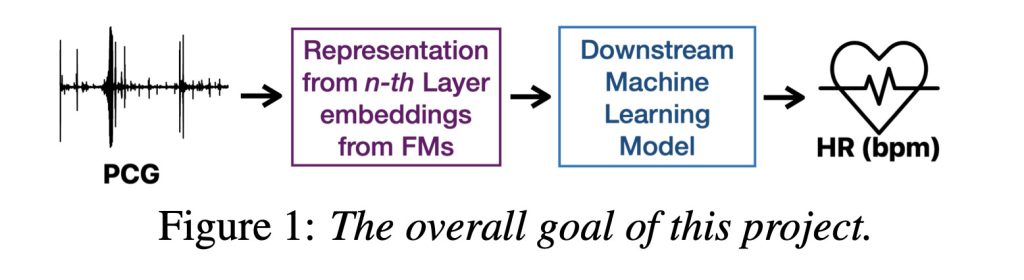
问题是:尽管这些模型不是为健康数据设计的,但结果却出奇地可靠。大多数模型的性能与依赖于手工制作的音频特征的旧方法一样好,这些特征是手动设计的表示声音的方式,长期以来一直用于传统的机器学习模型。
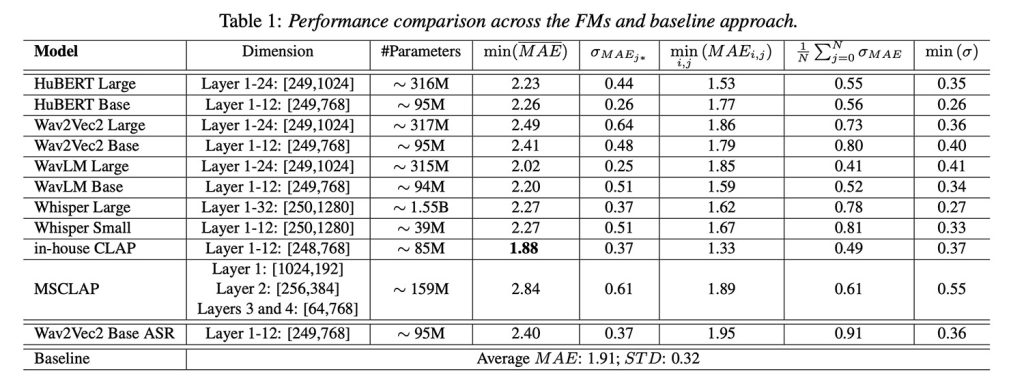
但最有趣的部分是什么?Apple 自己的内部模型是 CLAP(对比语言-音频预训练)的一个版本,在 300 万个音频样本上进行了内部训练,实际上性能优于基线,并在各种模型比较中提供了最佳的整体性能。
测试是如何进行的?
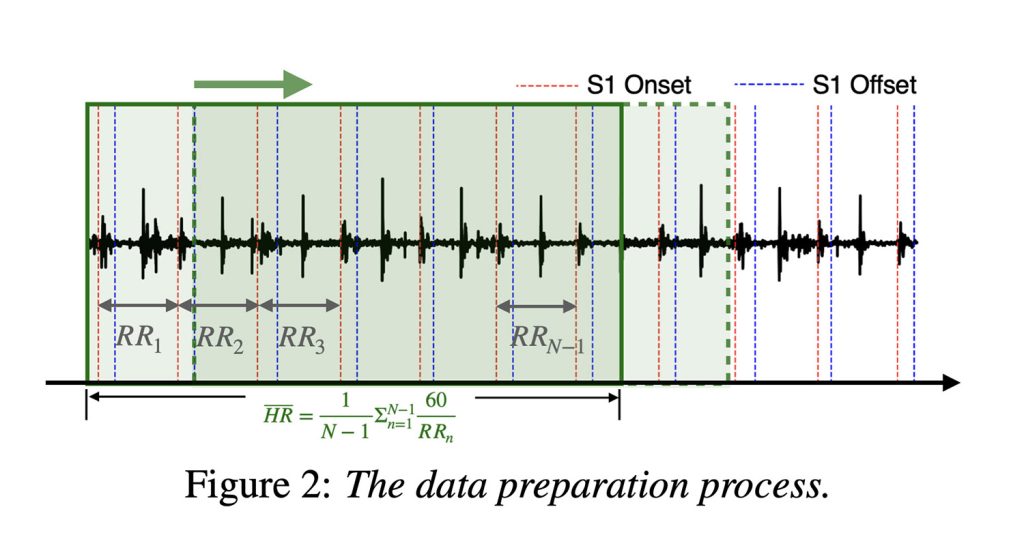
这些模型使用公开可用的数据集进行评估,该数据集包含超过 20 小时的真实医院心音,并由专家进行注释(这是良好的 AI 研究和性能的关键)。
为了训练模型,Apple 将录音分成 5 秒的短片段,一次向前移动一秒。这加起来大约有 23,000 个心音片段,然后 Apple 训练了一个神经网络,将心率分类为每分钟心跳次数值。
有趣的是,一些发现与典型的 AI 假设背道而驰:更大的模型并不总是表现得更好。在这些模型中获得更多技术性、更深层次的心肺信息通常会编码不太有用的心肺信息,这可能是因为它们针对语言进行了优化。浅层或中间层表示往往效果最好。
这是这项研究的关键见解之一。因为现在 Apple 知道该往哪里找里面这些模型以及使用哪些层来提取最相关的健康信号,如果 (更好的是,何时) 它决定将这种分析引入其设备。
关键要点
该研究的主要结论之一是,将老式信号处理与下一代 AI 相结合,可以产生更可靠的心率估计。这意味着,在一种方法难以克服的情况下,另一种方法通常会填补空白。基本上,这两种方法都会拾取信号的不同部分。
展望未来,研究人员表示,他们计划继续完善健康应用的模型,构建可以在低功耗设备上运行的更轻量级版本,并探索其他可能值得聆听的与身体相关的声音。或者,用他们自己的话说:
“未来,我们计划:(i) 探索将声学特征与 FM 表示相结合,在下游模型之前或通过模型内的后期融合方法使用特征连接,以提高性能,并研究此类方法是否能够捕获互补信息并对个体变化更具鲁棒性;(ii) 研究将 FM 微调到目标域以减少域不匹配,从而探索这种适应是否转化为性能的提高,更好地缓解 HR 估计中的挑战,并捕获复杂的病理特征;(iii) 评估他们对其他下游任务和生理 PA RAMS 的 AP 敏感性,包括病理条件;(iv) 增加和改编更多具有临床意义的数据;(v) 将它们与其他生物声学基础模型进行比较,例如 HeAR [30];(vi) 探索模型简化策略,例如修剪、蒸馏和轻量级编码器设计,以实现具有较低计算成本的可部署解决方案,同时保持性能。
该研究显然没有做出任何临床声明或产品承诺。尽管如此,当谈到 Apple 如何将这些型号嵌入 iPhone、Apple Watch,尤其是 AirPods 时,潜力是显而易见的,它们依靠入耳式麦克风进行主动降噪。如果您曾经在佩戴 AirPods 时听到过自己的耳内心跳,您就会知道我在说什么。
您可以在arXiv.