





苹果研究人员发布了一项研究,探讨大语言模型如何通过分析音频和运动数据来更全面地识别用户活动。以下是具体内容。
识别能力强,但不会令人不适
一篇题为《使用LLM进行活动识别的晚期多模态传感器融合》的新论文指出,苹果可能正考虑将LLM分析与传统传感器数据结合,以更精确地理解用户活动。
研究人员认为,即使在传感器数据不足的情况下,该方法也有巨大潜力提升活动分析的准确性。
研究团队表示:
“传感器数据流为下游应用提供了有关活动和背景的宝贵信息,但整合互补信息可能存在挑战。我们证明大语言模型可用于基于音频和运动时间序列数据的活动分类晚期融合。我们从Ego4D数据集中筛选了跨场景(如家务、运动)的多样化活动识别数据子集。评估的LLM在12类零样本和单样本分类中的F1分数显著高于随机概率,且无需任务特定训练。通过基于LLM的特定模态模型融合进行零样本分类,可在对齐训练数据有限的情况下实现多模态时序应用。此外,基于LLM的融合无需为特定应用的多模态模型增加额外内存和计算资源。”
换言之,大语言模型能通过基础音频和运动信号准确推断用户行为,即使未经专门训练。而在获得单个示例后,其准确性会进一步提升。
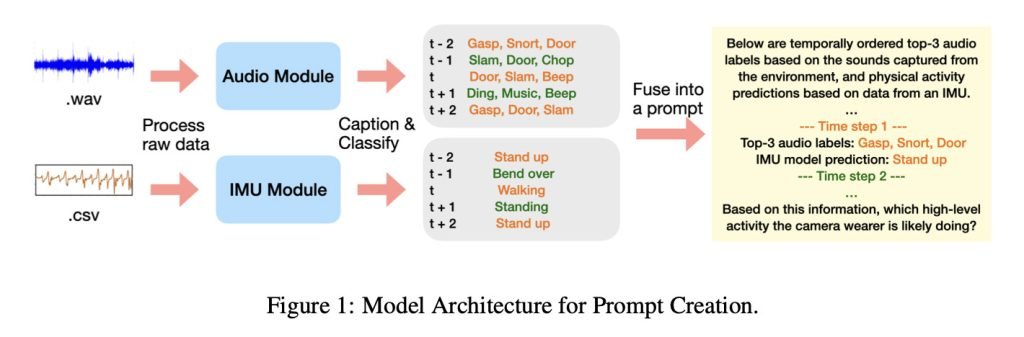
需特别说明的是,本研究未向LLM输入原始音频,而是提供了音频模型生成的文本描述和基于IMU的运动模型数据(通过加速度计和陀螺仪追踪运动),如下图所示:
深入探究
论文中指出,研究采用第一视角拍摄的海量数据集Ego4D,该数据集包含从家务到户外活动等数千小时真实环境记录。
研究说明:
“我们通过叙事描述筛选Ego4D数据集中的日常活动,最终选取12类高层活动:吸尘、烹饪、洗衣、进食、打篮球、踢足球、逗宠物、读书、用电脑、洗碗、看电视、健身/举重。这些活动覆盖家庭与健身场景,并基于数据集中出现频率选定。”
研究人员将音频和运动数据输入小型模型生成文本描述与分类预测,再将结果输入不同LLM(Gemini-2.5-pro与Qwen-32B)以评估活动识别能力。
苹果比较了两种情境下的模型表现:一是给定12种活动选项(封闭集),二是未提供选项(开放集)。测试组合包括音频描述、音频标签、IMU活动预测数据及额外背景信息,结果如下:
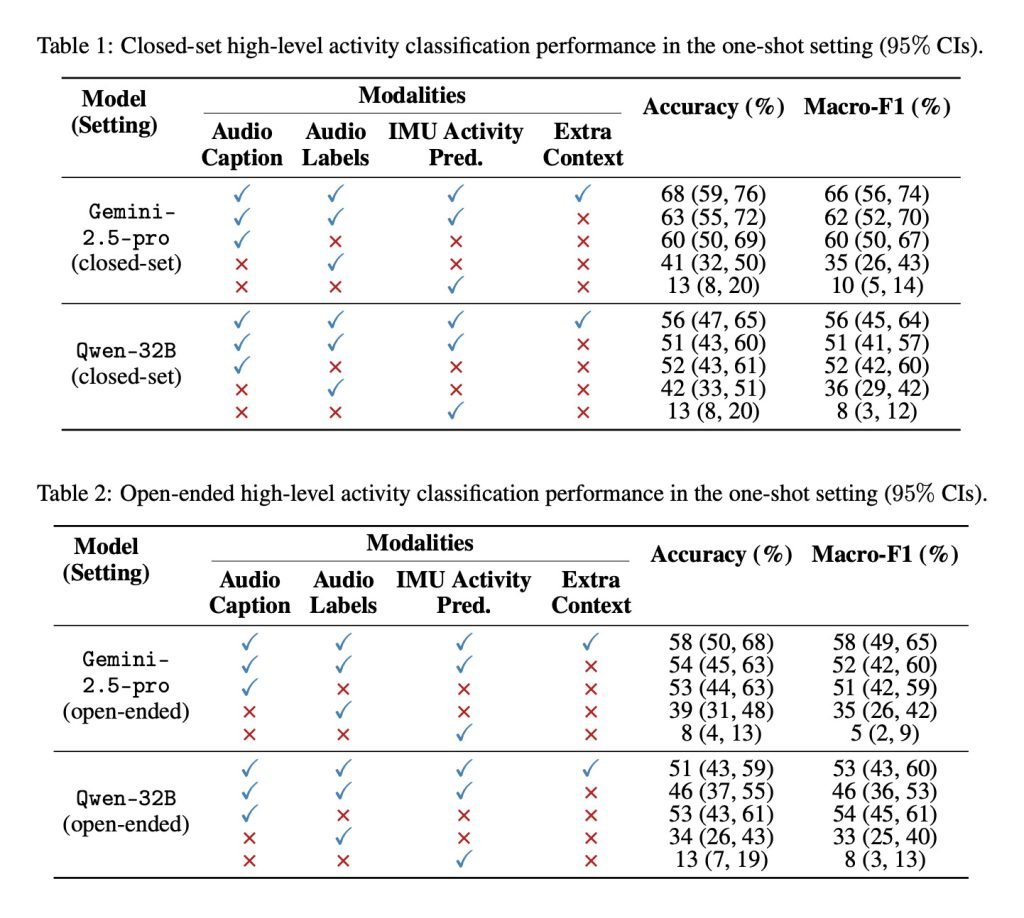
研究人员总结称,该研究为多模型融合提升活动与健康数据分析提供了新思路,尤其在原始传感器数据不足时效果显著。苹果同步公开了实验涉及的Ego4D片段ID、时间戳、提示词等辅助材料,便于学术复现。










