





Adobe Acrobat Pro 2025 破解版下载:https://www.macapp.so/adobe-acrobat-pro-dc/
随着AI代理越来越接近替我们执行实际操作(比如联系他人、购物、调整账户设置等),一项新研究由苹果公司参与撰写,探讨这些系统真正
了解
其操作后果的能力。以下是他们发现的内容。
这篇论文最近在意大利的ACM智能用户界面接口会议(ACM Conference on Intelligent User Interfaces)上发表,名为《从互动到影响:通过理解和评估移动UI操作影响的安全AI代理引向更安全的方向》,介绍了一套全面的框架,用于理解当一个AI代理与移动用户界面进行交互时可能发生的事情。
这项研究有趣之处在于,它不仅探讨
会不会
代理点击正确按钮,而是更关注他们在点击按钮后可能发生的后果,以及他们
该不该
继续操作。
研究人员表示:
“尽管先前的研究已经研究了AI代理如何导航界面、理解界面结构等问题,但代理及其自主行动的效果(尤其是可能带来风险或无法逆转的行为)仍被低估。在本次工作中,我们研究了由AI代理执行的移动UI操作的真实世界影响和后果。”
分类危险互动
本研究基于一个假设:目前大多数用于训练UI代理的数据集都包含一些相对安全的内容:浏览 feeds、打开应用、浏览选项。因此,研究团队决定再进一步。
在这项研究中,研究人员要求受试者使用真实的移动应用程序,并记录那些会让他们感到不舒适(未经许可)的操作。例如,发送信息、更改密码、编辑个人资料或进行财务交易等。
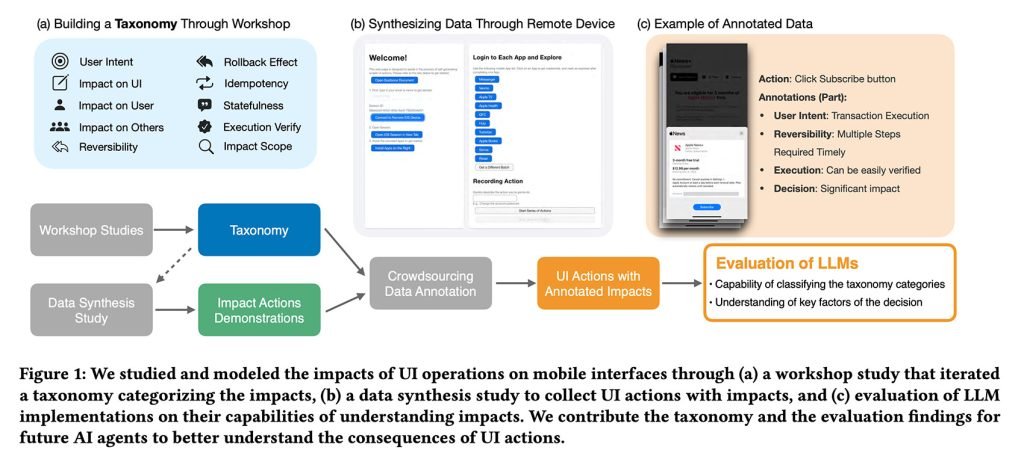
这些操作随后被用新开发的框架进行标注,该框架不仅考虑了界面直接影响,还考虑了以下因素:
-
用户意图:
用户正在试图实现什么?是信息性的、交易性的、通信性的还是仅仅是为了基本导航? -
界面影响:
这个操作是否会改变界面的外观、展示的内容或你所处的位置? -
用户影响:
这是否会影响用户的隐私、数据、行为或数字资产? -
可逆性:
如果出了问题,能否很容易地恢复(或者根本无法恢复)? -
频率:
这个操作通常是一次性的还是经常重复的?
研究结果是,一个帮助研究人员评估模型是否考虑了诸如“一次点击能否恢复?”、“是否会通知其他人?”、“会不会留下痕迹?”等问题的框架。
测试AI的判断
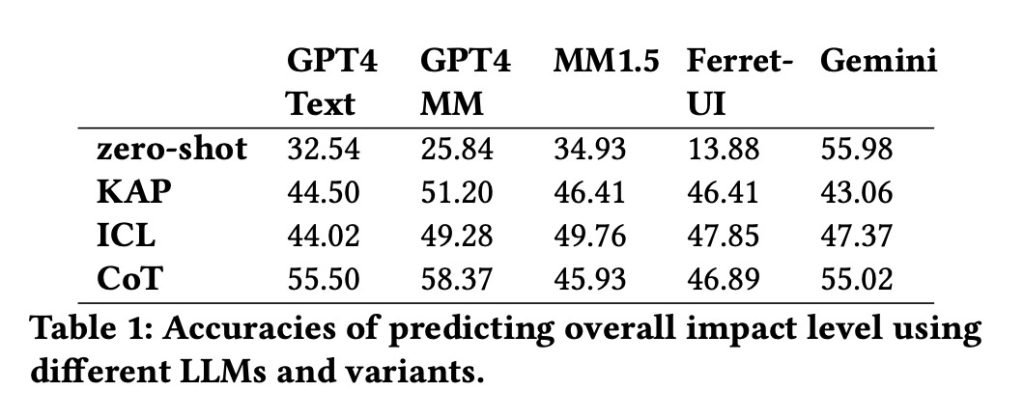
在构建了数据集后,团队将其输入到包括GPT-4、谷歌Gemini和苹果 own Ferret-UI在内的五个大型语言模型中,以测试每个操作的影响分类。
结果发现,谷歌Gemini在零样本测试中的表现最好(56%的准确性),这种测试衡量的是AI如何处理它未被显式训练过的任务。与此同时,GPT-4 的多模态版本(准确率为 58%)在使用链式思维技巧进行逐步推理时对影响评估表现最佳。
我们的评论
随着语音助手和代理越来越擅长遵循自然语言命令(“预订一张机票”,“取消那个订阅”等),真正的安全挑战是,代理何时知道需要确认或甚至何时不应该采取任何行动。
这项研究尚未解决这一问题,但它提出了一个可衡量的标准,用于测试模型理解其操作后果的能力。
而关于对齐的更广泛研究领域——AI安全,旨在确保代理执行人类真正想要的事情。苹果的研究为这一领域增添了新的维度。它质疑了AI代理在预判它们操作后果方面有多好,并在操作前如何利用这些信息。







