





苹果最新研究论文披露了一项在保持输出质量前提下加速大语言模型响应的技术。以下是具体细节。
技术原理
传统LLM采用逐标记生成方式,由于每个步骤都依赖前序输出保持连贯性,这种串行处理导致效率低下。
以生成句子”
The cat is black
“为例,模型在输出”
The cat is
“后,需要综合上下文、用户指令及训练模式,计算词汇表中所有可能后续标记的概率分布,这种机制称为自回归。
此时系统可能对
black
、
tall
、
sleeping
等候选词进行概率排序,最终选择最符合语境的选项。
技术创新
在《你的LLM预知未来:发掘多标记预测潜力》研究中,苹果团队发现:尽管模型通常仅训练预测下一标记,但其内部已隐含后续多个标记的有效信息。
基于此,他们开发了”多标记预测”(MTP)框架,实现单次生成多个标记。
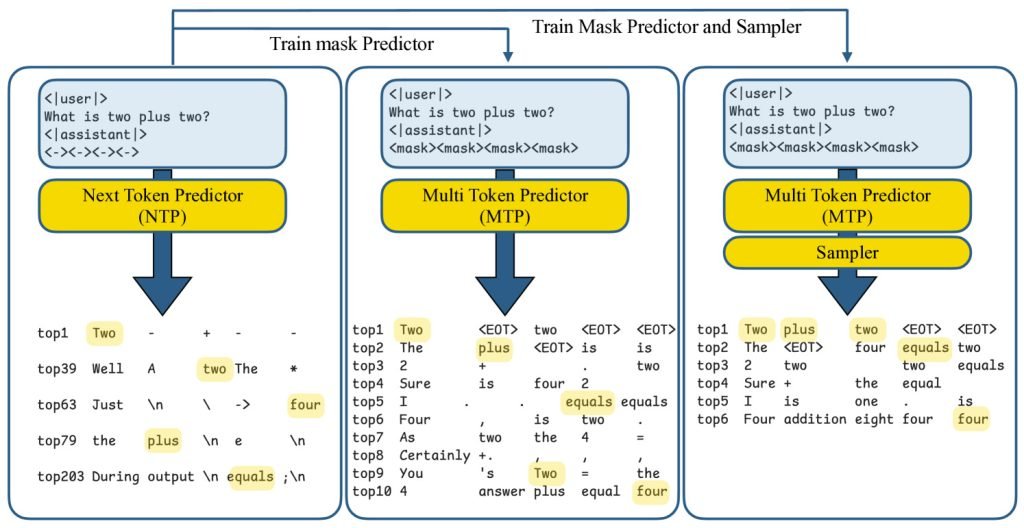
该技术与我们此前报道的扩散模型研究存在相似理念。虽然训练过程和底层技术不同,但两者都致力于突破逐标记生成的速度限制。
具体实现中,研究者在提示词插入特殊”掩码”标记作为占位符。例如”这只猫是
“可能单步填充为”
非常蓬松
“。系统同步推测多个后续词汇,并立即通过标准自回归解码验证。若推测失败则回退传统方式,确保速度提升不影响准确性。
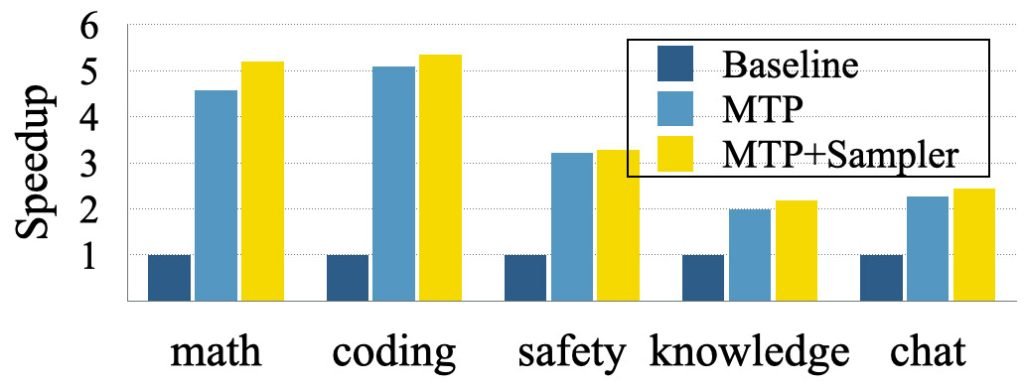
基于Tulu3-8B开源模型的测试显示:当训练模型预测8个额外标记时,问答和对话等常规任务加速2-3倍,编程和数学等可预测性强的领域最高达5倍。通过”门控LoRA适配”技术,这些增益未导致生成质量下降。
完整论文详见arXiv平台。