





苹果最新研究展示了一种扩散模型,其文本生成速度可达同类模型的128倍。以下是技术解析。
技术原理
研究背景要点:以ChatGPT为代表的自回归模型(LLMs)采用顺序生成机制,每次仅产生一个文本标记(token),同时参考用户指令和已生成内容。
扩散模型采用截然不同的并行生成策略,通过多轮迭代优化并行生成的文本标记,最终形成完整响应。
流匹配模型(flow-matching)作为扩散模型的变体,直接跳过迭代过程实现单步生成。
深入了解扩散模型可参阅苹果基于扩散的代码生成模型研究,流匹配模型细节请参考苹果蛋白质折叠流匹配模型论文。
突破性研究
在题为《FS-DFM:基于少步扩散语言模型的快速精准长文本生成》的最新研究中,苹果与俄亥俄州立大学联合提出Few-Step Discrete Flow-Matching模型(FS-DFM)。
实验数据显示,FS-DFM仅需8轮优化即可生成完整段落,其质量媲美需上千步迭代的传统扩散模型。
该研究采用三阶段创新方案:首先训练模型适应不同迭代预算;其次引入”教师”指导机制确保迭代更新的精准度;最后优化迭代过程实现更稳定的少步收敛。
在困惑度(perplexity)和熵值(entropy)两项核心指标上,FS-DFM均展现卓越性能。
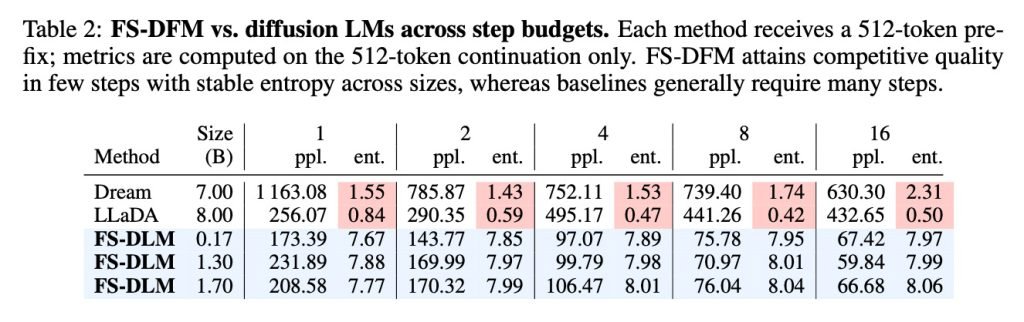
困惑度是衡量文本自然度的标准指标,数值越低表明生成质量越高。
熵值反映模型选择词汇的置信度,数值过低会导致文本重复,过高则可能产生语义混乱。
对比70亿参数的Dream扩散模型和80亿参数的LLaDA扩散模型,17亿/13亿/1.7亿参数的FS-DFM变体在所有迭代次数下均保持更优的困惑度与更稳定的熵值。
鉴于该方法的前景及领域空白,研究团队表示”计划公开代码和模型检查点以促进复现与后续研究”。
完整论文包含更多技术细节与可视化案例,例如这个通过颜色编码展示词汇迭代过程的示例:

图9:标记级生成时序。最终文本中每个标记的背景色对应其最后修改的迭代轮次(8种渐变色表示起始→结束)。早期稳定的标记呈现暖色调,局部优化与整体收敛过程清晰可见。多数黄色标记表明其在早期迭代即已确定。
论文《FS-DFM:基于少步扩散语言模型的快速精准长文本生成》详见arXiv平台。