





在WWDC25大会上,苹果发布了新一代终端和云端基础模型。如今该公司发布技术报告,详细阐述了这些模型的训练、优化和评估过程,其中包含诸多值得关注的技术细节。
这份题为《Apple Intelligence基础语言模型——2025技术报告》的文档,全面介绍了新模型的架构、数据来源、预训练与后训练流程、工具开发、优化方案以及基准测试等核心内容。
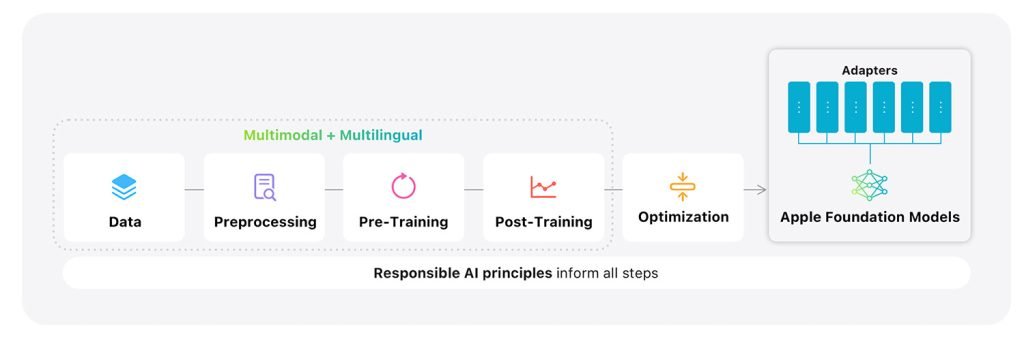
苹果基础模型架构概览。图片来源:Apple
虽然技术性较强,但对于希望深入了解AI模型构建细节的读者极具参考价值。以下是报告中几个尤为突出的技术亮点。
本地模型采用双模块设计
已知苹果终端模型(开发者可调用版本)包含约30亿参数。最新披露显示,该模型实际由两个模块组成:
“模块1包含62.5%的Transformer层,模块2包含剩余37.5%的Transformer层,但移除了键值投影结构。”
这种设计使本地模型缓存内存需求降低37.5%,首词元(即单词片段)输出耗时也减少约37.5%。苹果表示,这种分割方式在保证模型整体性能和输出质量的前提下实现了效率提升。
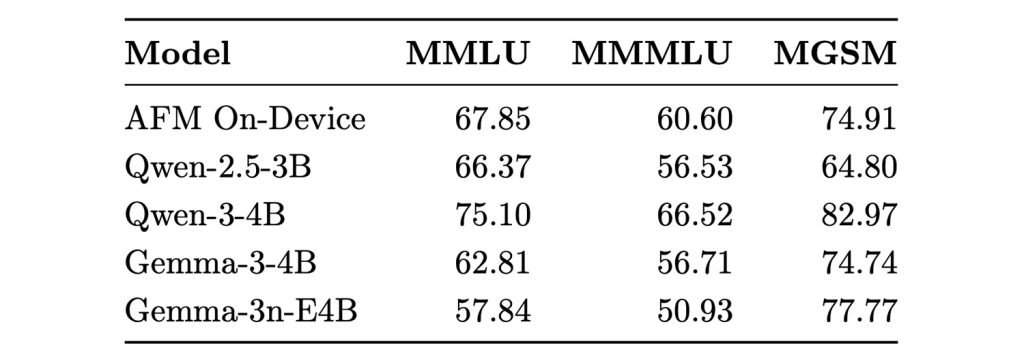
苹果终端模型与外部模型基准测试对比。图片来源:Apple
值得一提的是,苹果三年前曾发布研究,探讨通过动态调度LLM模块在RAM与闪存间的切换,实现在有限内存设备上运行超规格本地模型。虽然最终方案不同,但反映出苹果持续探索提升终端性能的创新路径。
云端模型采用创新架构
针对服务器模型,苹果专门为其私有云计算平台设计了名为”并行轨道专家混合(PT-MoE)”的创新架构。
简而言之,专家混合(MoE)技术将单一大型AI模型分解为多个专业子网络,仅激活与当前任务相关的专家模块。例如处理烹饪相关指令时,仅调用烹饪专家模块。
苹果首先开发了新型”并行轨道Transformer”,随后通过MoE层进行扩展。与传统单轨处理不同,该设计将模型分割为多个并行轨道,各轨道独立处理词元并在特定节点同步。每个轨道内,苹果用MoE层替代常规Transformer层,仅激活局部专家模块,避免系统级协调带来的性能瓶颈。
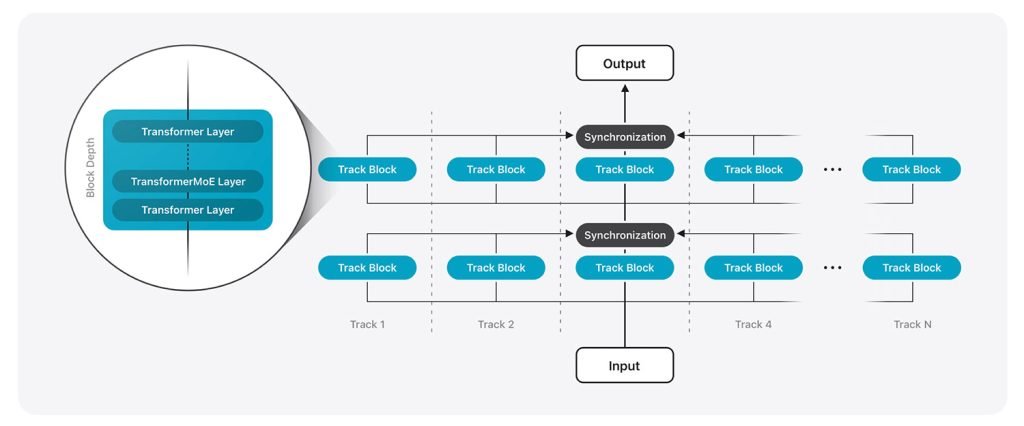
结合”全局与局部注意力层交错”机制平衡上下文理解,最终形成高效、可扩展的模块化架构,在保持智能水平的同时显著提升响应速度。
多语言支持提升275%
针对初期Apple Intelligence多语言支持不足的批评,新一代模型显著扩展了语言覆盖范围。报告显示,训练数据中多语言内容占比从8%提升至30%,包含自然语料与合成数据。
同时,模型词元库规模扩大50%,现支持15万词元(原为10万)。苹果表示这些改进使非英语基准测试成绩显著提升,特别是在强化学习微调后。
评估采用母语者撰写的提示(非翻译内容),测试涵盖准确性和语境自然度。这意味着”写作工具”等功能在支持语言中将表现更稳定。

训练数据来源解析
与初代模型类似,大部分训练数据来自网络爬取,但苹果强调其Applebot爬虫严格遵守robots.txt协议。具体数据来源包括:
- 公开网络数据:主要来自Applebot爬取的网页内容,经过多层过滤剔除低质、不安全或无关信息。
- 授权数据:部分数据获出版商授权,此前报道显示苹果曾与康泰纳仕、NBC新闻等机构洽谈内容授权。
- 合成数据:通过小模型和定制流程生成,主要用于数学、代码、指令调优等特定领域,在多语言支持等关键环节发挥重要作用。
- 视觉数据:包含超100亿图像-标题对,含OCR截图和手写笔记,并通过自有模型生成更丰富的描述文本。
媒体观点
尽管苹果在AI领域面临诸多挑战,这份报告揭示了其在隐私优先框架下的技术创新,展现出不同于行业常规的发展路径。