





苹果公司近日发布了包含40万张图像的Pico-Banana-400K研究数据集,有趣的是该数据集使用了谷歌Gemini-2.5模型构建。以下是具体细节。
苹果研究团队发表了一项名为《Pico-Banana-400K:面向文本引导图像编辑的大规模数据集》的研究。
除研究论文外,他们还发布了完整的40万张图像数据集,该数据集采用非商业研究许可协议。这意味着任何人都可以将其用于学术工作或AI研究目的,但不能用于商业用途。
那么这个数据集有什么用?
数月前,谷歌发布了Gemini-2.5-Flash-Image模型(又称Nanon-Banana),堪称当前图像编辑模型的技术标杆。
虽然其他模型也展现出显著进步,但正如苹果研究人员所言:
“尽管取得这些进展,开放研究仍受限于缺乏大规模、高质量且完全可共享的编辑数据集。现有数据集通常依赖专有模型的合成生成或有限的人工筛选子集。此外,这些数据集常存在领域偏移、编辑类型分布不均和质量控制不一致等问题,阻碍了稳健编辑模型的发展。”
为此,苹果决定采取行动。
构建Pico-Banana-400K
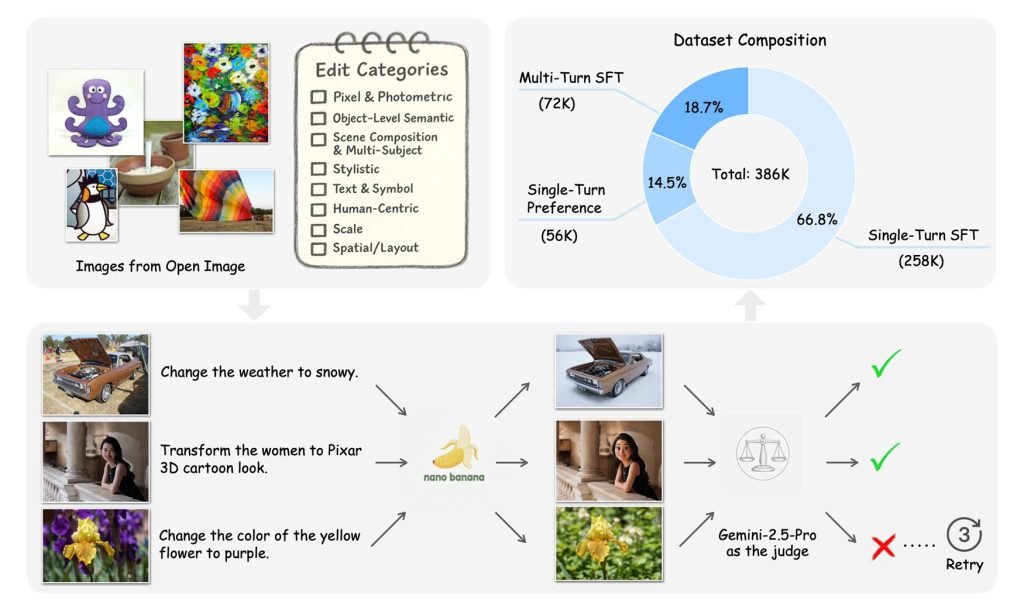
苹果首先从OpenImages数据集中选取了数量不详的真实照片,”确保覆盖人物、物体和文字场景”。
是的,他们确实使用了Comic Sans字体
随后团队列出了用户可能要求的35种修改类型,分为8个类别。例如:
- 像素和光度:添加胶片颗粒或复古滤镜
- 人物中心:将人物转换为Funko-Pop风格玩偶
- 场景构图和多主体:改变天气条件(晴天/雨天/雪天)
- 对象级语义:重新定位物体(改变其位置/空间关系)
- 比例:放大图像
研究人员将图像与修改指令一并输入Nano-Banana模型。生成编辑后的图像后,再用Gemini-2.5-Pro分析结果,根据指令遵循度和视觉质量进行通过或拒绝的判断。

最终形成的Pico-Banana-400K数据集包含:单次编辑图像(单一指令)、多次编辑序列(多重迭代指令),以及成功与失败结果的对比配对(让模型也能识别不良输出)。

尽管承认Nano-Banana在精细空间编辑、布局推断和字体排版方面的局限,研究人员表示希望Pico-Banana-400K能成为”训练和评估下一代文本引导图像编辑模型的坚实基础”。
研究论文可在arXiv获取,数据集已在GitHub开源。








